- リンクを取得
- ×
- メール
- 他のアプリ
PodCastでの音声配信
Fire Base Hostingを使用してのPodCast配信静的コンテンツ配信にFire Base Hostingが使えそうなので、ここからRSSフィードとmp3音声ファイルを配信します。
以前のBlogger連携と同様にFirebaseのAPIも管理できるように変更してください。
Fire Base Hostingの設定
Fire Baseコンソールにアクセスしてプロジェクトを作成します。
またプロジェクト内に入り「+アプリを追加」をクリックして、次に(</>)をクリックしてWebアプリケーションの設定ワークフローを起動します。
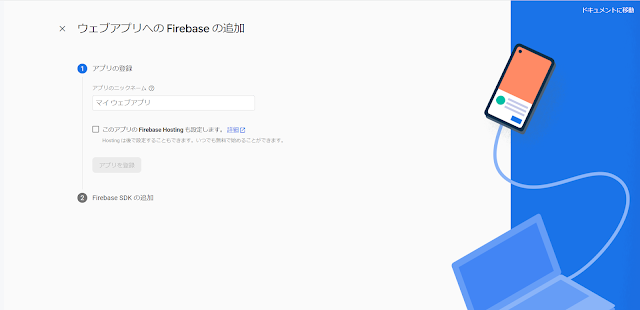
FireBaseHostingを有効にして、指示された通りにnpmを実行していくと、プロジェクトとアプリが作成されます。
作成が終わると表示されるプロジェクトの設定画面にあるプロジェクト-IDをプログラムの中で使うので覚えていてください。
また[プロジェクトの設定] > [サービス アカウント] を開きます。
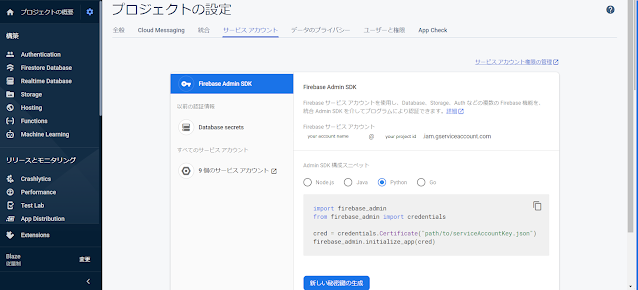
[新しい秘密鍵の生成] をクリックし、[キーを生成] をクリックして確定します。
キーを含む JSON ファイルを「firebase.json」ファイルとして保管します。
ライブラリの追加
$ pip install firebase_admin
Pythonプログラム
test.pyに以下のコードを記述します。
公式のサンプルを一部変更して持ってきています。
test.py
FIREBASE_SECRETS_FILE = "./firebase.json"
FIREBASE_HOSTING_URL = "https://firebasehosting.googleapis.com/v1beta1"
FIREBASE_HOSTING_SITE = FIREBASE_HOSTING_URL + "/sites/project-id"
def fb_getToken():
cred = credentials.Certificate(FIREBASE_SECRETS_FILE)
token = cred.get_access_token()
return token.access_token
def fb_getVersion(token):
url = FIREBASE_HOSTING_SITE + "/versions"
headers = {
'Content-Type': "application/json",
'Authorization': "Bearer " + token
}
response = requests.request("GET", url, headers=headers,timeout=REQUEST_TIMEOUT)
json_str = json.loads(response.text)
writeable_version = None
for version in json_str['versions']:
if 'CREATED' in version['status']:
writeable_version = version['name']
if writeable_version == None:
url = FIREBASE_HOSTING_SITE + "/versions"
response = requests.request("POST", url, headers=headers,timeout=REQUEST_TIMEOUT)
json_str = json.loads(response.text)
writeable_version = json_str['name']
return writeable_version
def fb_upload(token,version,path):
fb_files = []
params = {
'files' : {
}
}
headers = {
'Content-Type': "application/json",
'Authorization': "Bearer " + token
}
fnames = listup_files(path)
for fname in fnames:
gzname = fname + '.gz'
with open(path + fname,mode='rb') as f:
data = f.read()
with gzip.open('/tmp/'+gzname, mode='wb') as fp:
fp.seek(0)
fp.write(data)
with open('/tmp/'+gzname, mode='rb') as f:
gz_data = f.read()
hash = hashlib.sha256()
hash.update(gz_data)
hex = hash.hexdigest()
params['files']['/'+fname] = hex
fb_files.append({"hash":hex,"name":fname,"context":gz_data})
url = FIREBASE_HOSTING_URL + "/" + version + ':populateFiles'
response = requests.request("POST", url, headers=headers,data=json.dumps(params),timeout=REQUEST_TIMEOUT)
json_str = json.loads(response.text)
req_list = json_str['uploadRequiredHashes']
url = json_str['uploadUrl']
headers = {
'Content-Type': "application/octet-stream",
'Authorization': "Bearer " + token
}
for req in req_list:
for fb_file in fb_files:
if fb_file['hash'] == req:
context = fb_file["context"]
response = requests.request("POST", url + '/' + str(req), headers=headers,data=context,timeout=REQUEST_TIMEOUT)
def fb_finalyze(token,version):
url = FIREBASE_HOSTING_URL + "/" + version + '?update_mask=status'
params = {
'status' : 'FINALIZED'
}
headers = {
'Content-Type': "application/json",
'Authorization': "Bearer " + token
}
response = requests.request("PATCH", url, headers=headers,data=json.dumps(params),timeout=REQUEST_TIMEOUT)
def fb_deploy(token,version):
url = FIREBASE_HOSTING_SITE + "/releases?versionName=" + version
headers = {
'Content-Type': "application/json",
'Authorization': "Bearer " + token
}
response = requests.request("POST", url, headers=headers,timeout=REQUEST_TIMEOUT)
def postPodcast_fb(podcast_dir):
try :
makeFeedXml(podcast_dir)
token = fb_getToken()
version = fb_getVersion(token)
fb_upload(token,version,podcast_dir)
fb_finalyze(token,version)
fb_deploy(token,version)
except Exception as e:
print (e)
このpostPodcast_fb()をgetRss()から呼び出します。
test.py
def getRss():
with open('/tmp/temp.mp3' ,mode='wb+') as f:
f.truncate(0)
rssUrl = 'https://news.google.com/news/rss/headlines/section/topic/TECHNOLOGY'
rssLang = '?hl=en-US&gl=US&ceid=US:en'
feed = feedparser.parse(rssUrl + rssLang)
for entry in feed.entries:
link = entry.get('link')
getBody(link)
postPodcast_fb('/tmp/')
ともかくこれでポッドキャストの自動アップロードがGoogleサービスだけでできました!
私のポッドキャストを公開しているのでよかったら聴いてください。
Apple Podcast
Google Podcast
Amazon Podcast
参考URL:
https://firebase.google.com/docs/web/setup
https://firebase.google.com/docs/hosting/quickstart
https://firebase.google.com/docs/hosting/api-deploy